How It Works
High-Level Architecture
Section titled “High-Level Architecture”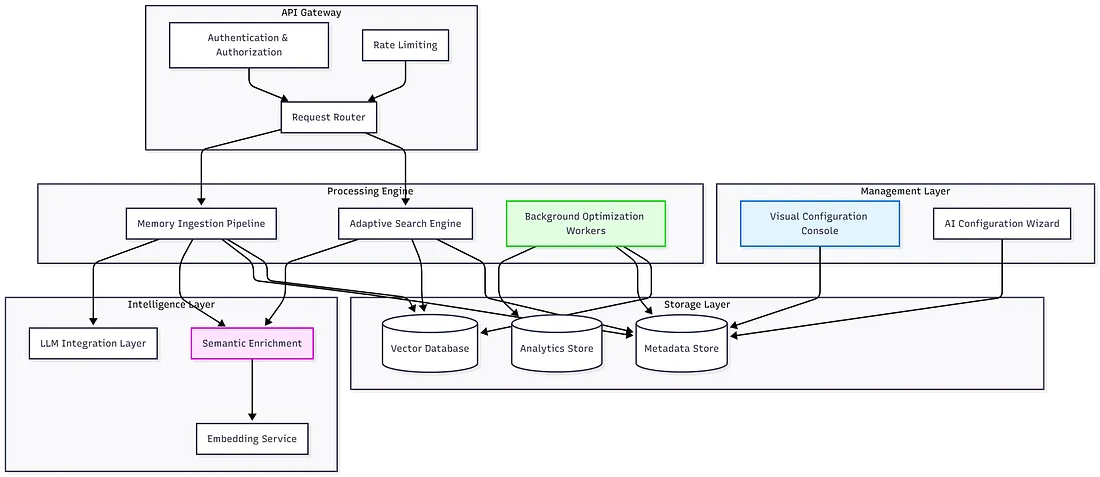
Architectural Principles
Section titled “Architectural Principles”The system design is governed by five core principles:
- Separation of Concerns: Clear logical boundaries are enforced between ingestion (write), retrieval (read), and optimization (background) processes.
- Distributed Processing: High-volume ingestion is handled via async queues to absorb load without blocking the retrieval pipeline.
- Dual-Write Consistency: The system enforces synchronized persistence between the Metadata Store and Vector Database to ensure index integrity.
- Horizontal Scalability: The API layer is stateless, enabling automatic scaling across nodes.
- Schema Agnosticism: The architecture supports User-defined memory schemas via the Console without requiring code changes.
Component Layers
Section titled “Component Layers”1. Management Layer
Section titled “1. Management Layer”- Visual Configuration Console: A React SPA for zero-code configuration and schema definition.
- AI Configuration Wizard: Automated tool for generating system configurations.
2. API Gateway
Section titled “2. API Gateway”- Request Router: Stateless serverless functions that route traffic to the appropriate engine.
- Rate Limiting & Auth: Managed services handling security and throughput control.
3. Processing Engine
Section titled “3. Processing Engine”- Ingestion Pipeline: Async extraction and validation engine.
- Adaptive Search Engine: The core logic for intent detection and strategy routing.
- Optimization Workers: Background processes that handle deduplication, parameter tuning, and centroid calibration.
4. Intelligence Layer
Section titled “4. Intelligence Layer”- Cloud AI APIs: Abstraction layer for LLM integration, pattern detection, and embedding generation.
- Semantic Enrichment: Service responsible for bidirectional context expansion.
5. Storage Layer
Section titled “5. Storage Layer”- Metadata Store: NoSQL Database handling ACID transactions and configuration.
- Vector Database: Managed Vector Store for high-performance similarity search.
- Analytics Store: Time-Series Database for recording retrieval telemetry and optimization feedback.