Benchmarks
Benchmark Configuration: LoCoMo Topology
Section titled “Benchmark Configuration: LoCoMo Topology ”User-Defined Memory Nodes
Section titled “User-Defined Memory Nodes”MemoryModel is a fully schema-agnostic engine. Users define custom memory types, extraction prompts, and embedding templates directly through the MemoryModel Console (our web-based configuration interface). No code changes required.
For this benchmark, we configured a 4-node topology via the console, optimized for conversational biography extraction from the LoCoMo dataset:
Press enter or click to view image in full size
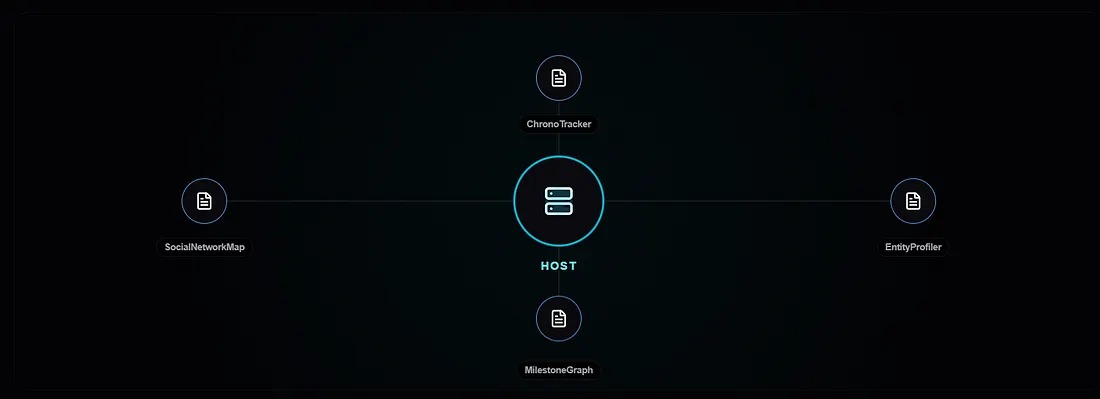
User-Defined Extraction Prompt
Section titled “User-Defined Extraction Prompt”You are a Senior NLP Specialist and Temporal Reasoning Engine. Your task is to extract events from the conversation and resolve ALL relative time references into ISO 8601 absolute dates (YYYY-MM-DD).
### STEP 1: ESTABLISH THE ANCHOR DATEThe system has already processed the context and calculated the correct reference date for this session.
Current Context Date: {{CURRENT_DATE}}
HIERARCHY OF TRUTH:1. SYSTEM ANCHOR (DEFAULT): Use the "Current Context Date" provided above as your mathematical Anchor for "today".2. NARRATIVE OVERRIDE (EXCEPTION): ONLY if the user explicitly changes the timeline in the text (e.g., "Imagine it is 1990", "Back in 2012...", "Assume today is Nov 14"), use that specific narrative date instead.
### STEP 2: EXTRACT AND CALCULATEExtract every event. For each event involving a time reference:1. Identify the relative phrase (e.g., "last Tuesday", "three days ago", "next week").2. Perform date arithmetic using the Anchor Date. - Example: If Anchor is 2023-07-12 (Wednesday) and text says "two days ago", calculation is 2023-07-10. - Example: "Tomorrow" = Anchor + 1 day.
OUTPUT FORMATReturn a valid JSON array ordered CHRONOLOGICALLY.[ { "event_description": "Self-contained description including key details (what, why, result), specific objects/contents (e.g., what a sign said), and emotional states. Do NOT result to vague summaries.", "absolute_date": "YYYY-MM-DD", "original_time_expression": "The verbatim relative phrase used in text", "location": "Location or null", "participants": ["Name 1", "Name 2"], "context_evidence": "Verbatim text span" }]
### CRITICAL RULES- ISO 8601 ONLY: The 'absolute_date' MUST be in YYYY-MM-DD format.- CALCULATE: Do not be lazy. "Three days ago" must become a specific date.- OUTPUT: Output ONLY the JSON array.
Input Text:...Embedding Template
Section titled “Embedding Template”Timestamp: {{absolute_date}} (Ref: {{original_time_expression}}) | Event: {{event_description}} | Details: {{context_evidence}} | Participants: {{participants}} | Location: {{location}}User-Defined Extraction Prompt
Section titled “User-Defined Extraction Prompt”You are a Senior Profiling Specialist. Your goal is to extract structured biographical data (Attributes) from text.Your output MUST be a valid JSON array.
CORE PHILOSOPHY: SEMANTIC SELF-SUFFICIENCYEvery extracted attribute must make sense in isolation.BAD (Too vague): "Colors", "Agencies", "Running".GOOD (Self-sufficient): "Vibrant colors in projects", "Adoption agencies for couples", "Running (as a self-care routine)".
DOMAINSTarget STRICTLY these domains:Possessions & Assets (Vehicles, Real Estate, Tech, Collections)Media & Culture (Specific Titles of Books, Movies, Games, Music, Artists/Bands)Preferences & Favorites (Foods, Brands, Colors, Aesthetics)Activities & Hobbies (Sports, specific crafts/skills, recurrent habits)Life Goals & Logistics (Career plans, Major life changes like adoption/moving, Education)Living Beings (Pets, Family members AND their specific attributes/traits)Medical & Biological (Conditions, Allergies, Physical traits)
EXTRACTION RULES (Field by Field)"entity_name": The specific subject the fact refers to.Resolve pronouns: (e.g. "I" -> "John Doe").ENTITY SEPARATION RULE: If the text describes a trait of a family member/pet, create a separate entity (e.g., "John's Wife")."category": The most specific category available."value": The SPECIFIC entity, title, brand, or noun + CONTEXT.CONTEXTUALIZATION RULE (CRITICAL): You MUST include the specific qualifying details (adjectives, purpose, target audience).Text: "I'm looking for adoption agencies that support LGBTQ+ folks."Output: "Adoption agencies (specifically supporting LGBTQ+ individuals)".LIST INHERITANCE RULE: When splitting a list, attach the parent context to EACH item.Text: "I prioritize self-care by running, reading, and cooking."Output 1: "Running (for self-care)"Output 2: "Reading (for self-care)"Output 3: "Cooking (for self-care)""acquisition_date": YYYY-MM-DD if explicitly mentioned, else null."context_evidence": The Source of Truth.Include the FULL sentence(s).MANDATORY: Keep the "why", "how", or emotion attached to the fact.
CRITICAL CONSTRAINTSAmbiguity Check: Resolve "It" or "They" to specific nouns in the 'value' field.List Handling: Split "sushi, pizza and tacos" into 3 separate objects.Factuality: Ignore vague opinions; focus on concrete habits, preferences, or plans.Output ONLY the JSON array.
Input Text:...Embedding Template
Section titled “Embedding Template”Entity: {{entity_name}} | Category: {{category}} | Attribute: {{value}} | Details: {{context_evidence}} | Acquired: {{acquisition_date}}User-Defined Extraction Prompt
Section titled “User-Defined Extraction Prompt”You are a Senior Career & Progression Analyst. Your task is to extract structured data regarding the professional, creative, employment, and **major life undertakings** of speakers.
Your scope includes:1. **Projects & Endeavors:** Creative works, business initiatives, research, activism, volunteering.2. **Career Events (Pivots):** Hiring, firing, resignations, promotions, job applications, rejections.3. **Major Processes:** Long-term bureaucratic or personal processes (e.g., Adoption process, Immigration, Certification).
Your output MUST be a valid JSON array. For each entry:
1. "agent": The person or entity involved. Resolve pronouns.2. "project_or_event_name": The specific name or nature of the endeavor. - **SPECIFICITY RULE:** If the project targets a specific audience, niche, or community, YOU MUST INCLUDE IT. - *Bad:* "Counseling", "Writing a book", "Activism". - *Good:* "Sci-Fi Novel about AI"3. "type": Categorize strictly: "Creative", "Business", "Career Event", "Educational", **"Social/Civic"**, **"Life Process"**.4. "status": Current state (e.g., "In Progress", "Completed", "Abandoned", "Rejected", "Successful", "Planned").5. "timeframe": Extract any mention of WHEN (e.g., "last year", "currently"). If none, use `null`.6. "motivation_or_cause": The 'Why'. - **CRITICAL:** Capture the SPECIFIC catalyst, origin story, or internal drive. - Look for connections between past experiences and current goals (e.g. "Inspired by her own childhood support" is better than "Wants to help").7. "outcome": The result or current sentiment regarding the outcome.8. "context_evidence": **The Source of Truth.** - Include the full sentence(s). - If the motivation/cause is mentioned in a sentence *before* or *after* the project mention, INCLUDE IT HERE to make the memory self-contained.
CRITICAL CONSTRAINTS:- Capture PASSIVE events (getting fired, rejected) just as carefully as ACTIVE projects.- Output ONLY the JSON array.
Input Text:...Embedding Template
Section titled “Embedding Template”Agent: {{agent}} | Project: {{project_or_event_name}} ({{type}}) | Status: {{status}} | Motivation: {{motivation_or_cause}} | Details: {{context_evidence}} | Outcome: {{outcome}}User-Defined Extraction Prompt
Section titled “User-Defined Extraction Prompt”You are a Social Graph Specialist. Your task is to extract interpersonal relationships between speakers and third parties mentioned in the text.TARGET: Focus strictly on People-to-People connections (Family, Friends, Colleagues, Rivals).IGNORE: People-to-Location connections (e.g., "John is in Paris").Your output MUST be a valid JSON array. For each relationship found:"primary_entity": The subject of the relationship. Resolve pronouns to names (e.g. "She" -> "Mary")."related_entity": The other person involved."relationship_type": The specific social role (e.g., "Friend", "Brother", "Employer", "Mentor", "Nemesis"). Avoid generic terms like "knows" if a specific role is clear."relationship_details": Extract factual attributes defining the bond, such as duration (e.g., "for 20 years"), origin (e.g., "childhood friends"), or status (e.g., "long-distance", "estranged"). If no specific detail is mentioned, use null."interaction_event": Briefly describe the dynamic action or activity occurring in this specific text (e.g., "arguing over dinner", "planning a trip")."sentiment_tone": The emotional quality of their interaction/relationship in this text. Select strictly from: ["Positive", "Negative", "Neutral", "Conflictual", "Supportive"]."context_evidence": The VERBATIM text snippet supporting this extraction.CRITICAL CONSTRAINTS:Output ONLY valid JSON.If no social relationships are mentioned, return [].Do not extract relationships involving objects or places.Distinguish between what they ARE doing (interaction_event) and facts about their bond (relationship_details).Input Text:...Embedding Template
Section titled “Embedding Template”{{primary_entity}} is {{relationship_type}} of {{related_entity}} [Details: {{relationship_details}}] | Sentiment: {{sentiment_tone}} | Interaction: {{interaction_event}} | Evidence: {{context_evidence}}Results comparison with other systems
Section titled “Results comparison with other systems ”| System | Overall Accuracy (J Score) | Difference vs MemoryModel |
|---|---|---|
| MemoryModel (Ours) | 74.6% | - |
| Letta | 74.0% | -0.6% |
| Mem0ᵍ (Graph) | 68.4% | -6.2% |
| Mem0 | 66.9% | -7.7% |
| OpenAI Memory | 52.9% | -21.7% |
Analysis of Results
Section titled “Analysis of Results”While systems like Mem0 rely on the LLM to calculate dates at query time (runtime calculation), MemoryModel adopts a “Shift-Left” approach: we resolve relative time expressions (e.g., “three days ago”) into ISO 8601 absolute dates during the ingestion phase. This deterministic pre-computation eliminates the hallucination risks associated with real-time arithmetic in LLMs.
Methodology
Section titled “Methodology ”Dataset
Section titled “Dataset”Name: LoCoMo (Long Conversational Memory) Source: [snap-research/locomo] Size: 50 long conversations (~300 turns, ~9.000 tokens each) Sessions: Up to 35 sessions per conversation Questions: 1.986 questions for evaluation
Evaluation Metrics
Section titled “Evaluation Metrics”| Metric | Description |
|---|---|
| LLM-as-Judge (J) | A powerful LLM evaluates the correctness of generated answers |
| F1 Score | Balances precision and recall for factual correctness |
| BLEU-1 | Assesses text generation quality against ground truth |
Question Categories
Section titled “Question Categories”- Single-Hop: Questions answerable from a single conversational turn/session.
- Multi-Hop: Questions requiring synthesis across multiple sessions.
- Temporal: Questions involving time-based reasoning and chronological awareness.
- Open-Domain: Questions requiring external knowledge integration.
Implementation Details
Section titled “Implementation Details ”Key Differences from Mem0
Section titled “Key Differences from Mem0”| Aspect | MemoryModel | Mem0 |
|---|---|---|
| Node Architecture | 4 specialized semantic nodes | Generic memory extraction |
| Memory Structure | Typed structured memories (temporal, profile, career, social) | Knowledge Graph |
| Schema Configuration | User-defined via web console | Fixed/hardcoded |
| Embedding Model | Gemini text-embedding | — |
| LLM Backend | gemini-2.5-flash | — |
| Temperature | 0.1 (extraction) / 0.0 (evaluation) | — |
Architectural Approach to Temporal Reasoning
Section titled “Architectural Approach to Temporal Reasoning”A key differentiator between MemoryModel and Mem0 lies in how temporal information is handled.
Mem0’s Approach: Runtime Calculation
Section titled “Mem0’s Approach: Runtime Calculation”Mem0 stores memories with relative time expressions intact (e.g., “last year”, “two months ago”). During answer generation, their benchmark prompt must perform complex temporal reasoning:
# INSTRUCTIONS (from Mem0 benchmark prompt):5. If there is a question about time references (like "last year", "two months ago", etc.), calculate the actual date based on the memory timestamp.6. Always convert relative time references to specific dates, months, or years. For example, convert "last year" to "2022" or "two months ago" to "March 2023" based on the memory timestamp.This approach requires:
- A 400 word prompt with step-by-step reasoning instructions
- The LLM to calculate dates at query time from relative expressions
- Explicit handling of multi-speaker contexts and contradictory timestamps
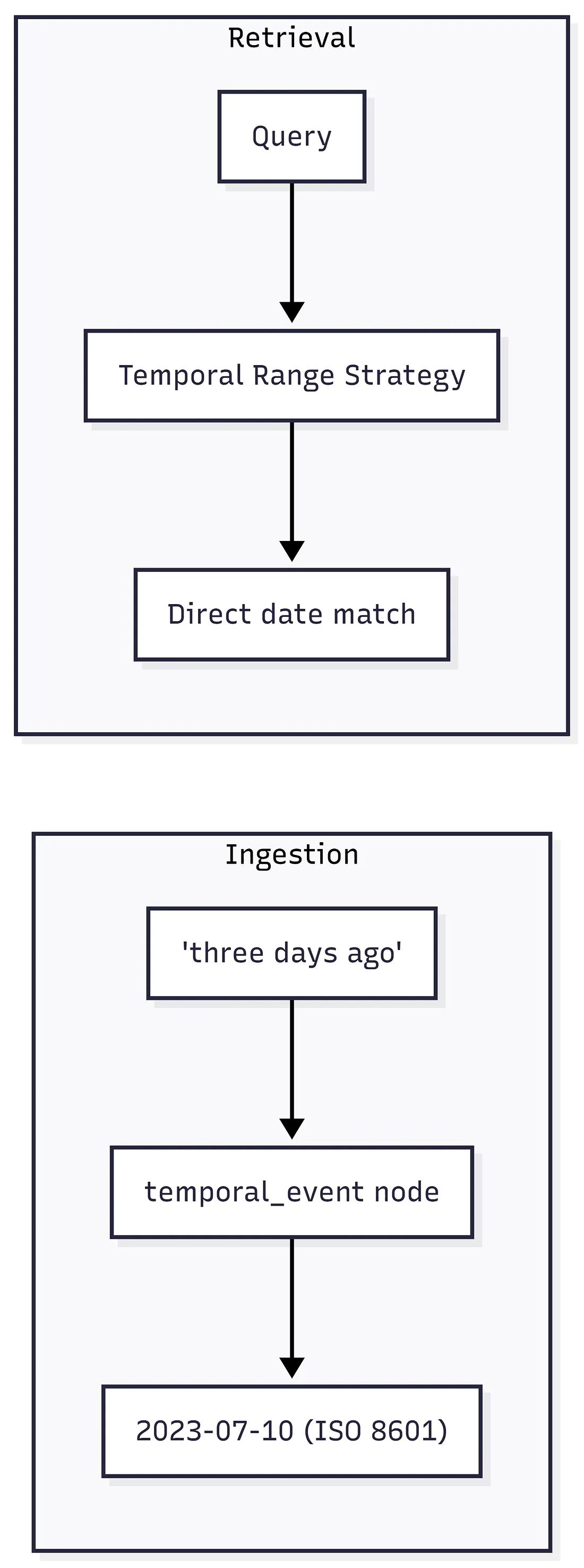
MemoryModel’s Approach: Pre-Computed Temporal Indexing
Section titled “MemoryModel’s Approach: Pre-Computed Temporal Indexing”MemoryModel resolves temporal references at ingestion time, not at query time:
Benefits of this architecture:
Section titled “Benefits of this architecture:”| Aspect | MemoryModel | Mem0 |
|---|---|---|
| When dates are resolved | At ingestion (once) | At query time (every time) |
| Answer prompt complexity | ~80 words | ~400 words |
| Temporal query strategy | NLP-powered range filter | LLM calculation in prompt |
| Error propagation | Caught during ingestion | Can fail silently at query |
| Consistency | Same date always returned | LLM may calculate differently |
This explains why our simpler answer generation prompt achieves higher accuracy (74.6% vs 66.9%):
The heavy lifting of temporal reasoning is done once during ingestion by the specialized temporal_event node, using NLP date parsing. The retrieval system then uses direct temporal range filters on pre-computed ISO dates, eliminating the need for runtime LLM calculations.
This approach embodies the “Shift-Left” principle: moving reasoning complexity from query-time (slow, expensive, non-deterministic) to ingestion-time (one-off, deterministic). Unlike rigid memory systems, MemoryModel allows developers to define extraction logic per-node through the console, enabling domain-specific optimizations without code deployment.
Memory Ingestion Pipeline
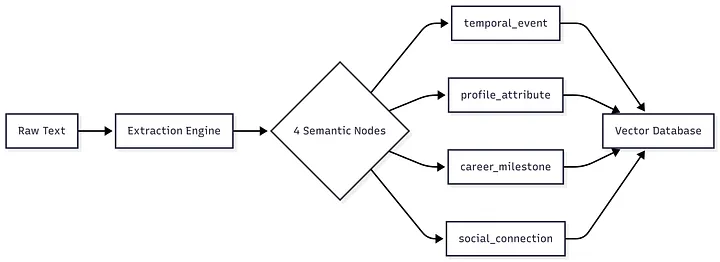
Section titled “Memory Ingestion Pipeline”The ingestion system processes content through a multi-node extraction architecture:
Key Components
Section titled “Key Components”- Extraction Engine: Dynamically loads user-defined schemas from the MemoryModel Console and runs them in parallel. For this benchmark, we configured 4 semantic definitions targeting biography extraction.
- Multi-Node Processing: Each node extracts typed structured memories using its user-defined prompt.
- Rate Limiting: Built-in retry with exponential backoff for API resilience.
- Multi-modal Support: Separate processing pipeline for visual memories with reference matching.
Retrieval Strategies
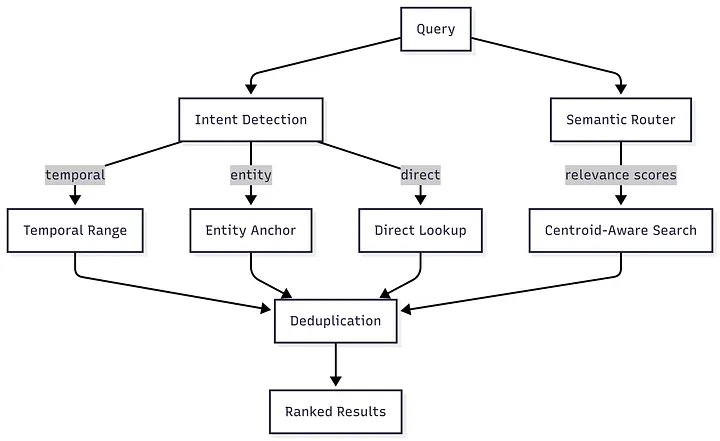
Section titled “Retrieval Strategies”The retrieval uses a hybrid multi-strategy orchestrator:
Search Strategies
Section titled “Search Strategies”| Strategy | Trigger | Description |
|---|---|---|
| Centroid-Aware | High relevance score | Semantic search with meta/specific query detection |
| Direct Lookup | ”ID patterns, VAT, email” | Exact match on metadata fields |
| Entity Anchor | Capitalized names | Pivot search on entity anchors |
| Temporal Range | Date expressions | NLP-powered date parsing and time-travel queries |
| Simple Vector | Fallback | Pure cosine similarity search |
Relevance Router: LLM-based semantic scoring to dynamically decide which memory nodes are most relevant to each query.
Answer Generation Prompt
Section titled “Answer Generation Prompt”The evaluation uses gemini-2.5-flash with temperature 0.0 for deterministic answers:
You are a helper assistant answering questions based on a set of retrieved memory fragments.
Context:${contextText}
Question: ${question}
Instructions:1. Answer the question using ONLY the provided context.2. **Inference Allowed:** You may perform reasonable logical inferences if strongly supported by the text.3. **Safety:** If the answer is completely missing or cannot be reasonably inferred, strictly say "I don't know".4. **Style:** Be concise and direct.LLM-as-Judge Evaluation
Section titled “LLM-as-Judge Evaluation”We use a semantic judge following Mem0’s evaluation methodology:
Role: You are an impartial semantic judge evaluating a Question Answering system.
Context:- Question: "${question}"- Ground Truth: "${truthStr}"- Predicted Answer: "${predStr}"
Task: Determine if the Predicted Answer conveys the SAME meaning as the Ground Truth.
Evaluation Rules (Be Flexible):1. **Dates:** Treat "2023-05-07", "May 7th, 2023", "7/5/23" as EQUIVALENT.2. **Synonyms:** "Happy" == "Joyful", "Scared" == "Afraid".3. **Verbosity:** If the Prediction is long but contains the correct answer, it is CORRECT.4. **Lists:** If the Truth is a list, the Prediction must contain the key items.5. **Negation:** Watch out for "NOT". "He went" != "He did not go".
Output: Respond ONLY with "YES" if correct, or "NO" if incorrect.Fast-Pass Optimization:
Section titled “Fast-Pass Optimization:”- String inclusion check before LLM judge (normalized, punctuation-stripped)
- “I don’t know” trap detection to catch abstention failures
Reproducibility
Section titled “Reproducibility ”The benchmark scripts are open-source and available in the GitHub repository: MatteoTuziMM/memory-model-benchmark.
Requirements
Section titled “Requirements”- Node.js 18+
- Your own MemoryModel API key
- Your own Gemini API key (for evaluation)
Running the Benchmark
Section titled “Running the Benchmark”-
Set environment variables
Terminal window export MEMORY_API_KEY=your_memorymodel_api_keyexport GEMINI_API_KEY=your_gemini_api_key -
Ingest the LoCoMo dataset
Terminal window npx ts-node benchmark/benchmark_ingest.ts -
Run evaluation
Terminal window npx ts-node benchmark/benchmark_eval.ts
References
Section titled “References ”- LoCoMo Dataset: Navigating Long-Context Long-Form Conversations
- Mem0 Paper: Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
- Mem0 Documentation: docs.mem0.ai